gc tuner¶
基本总结和目标¶
目标:为公司内部cpu quota较大的服务节省CPU使用量。
统计口径:在12.12 campaign开始后的1h。
服务数量:67 实例总数量116k:,gc tuner影响数目:49k, 覆盖率42%。未完全覆盖原因:为了完成精确的收益计算,去除系统级别的噪音。42%是因为组件内部的runtime toggle依赖容器部署设置的参数来做分片。
总配置CPU quota:682K Core 总配置内存量:1.11PB
Memory和CPU¶
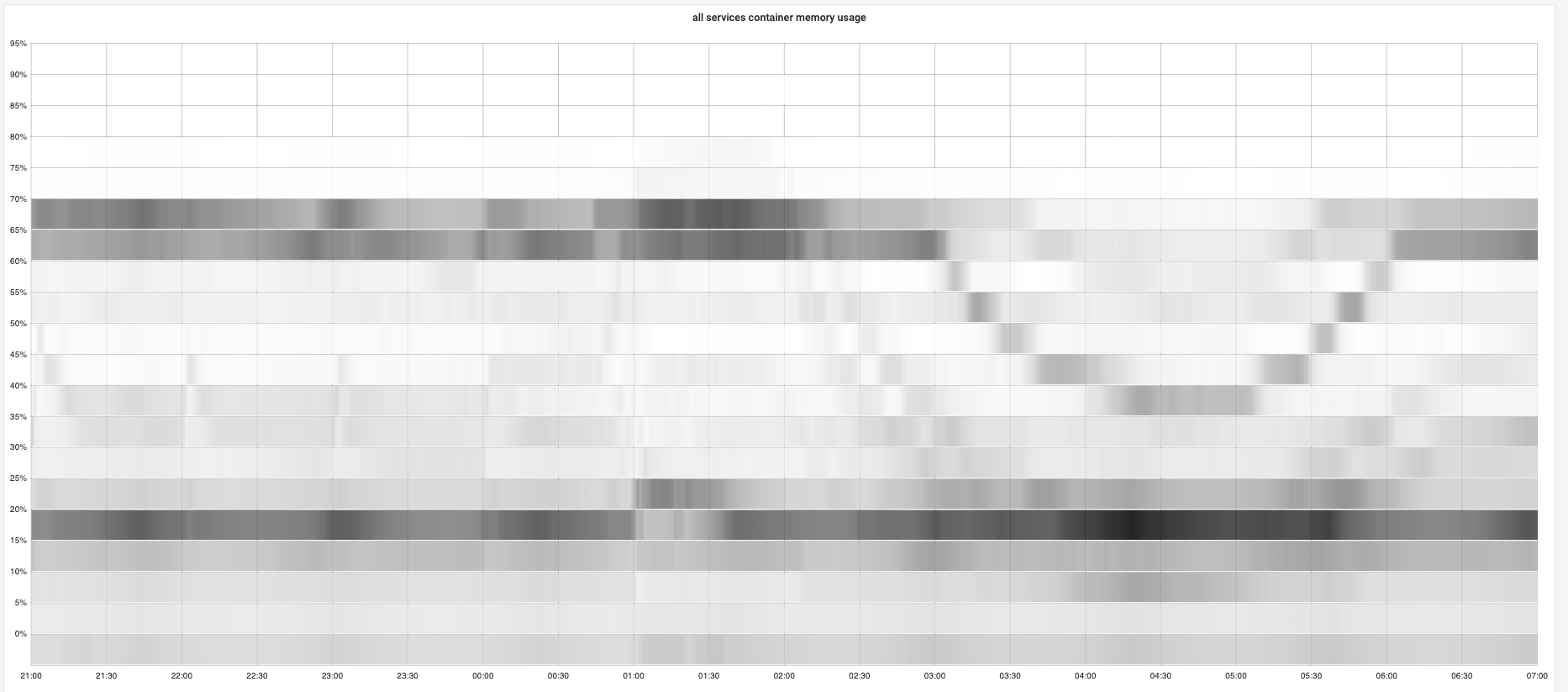
内存和CPU分布图(TODO: 由于baseline缺乏metrics所以暂时只有deviation版本的图):
baseline和feature¶
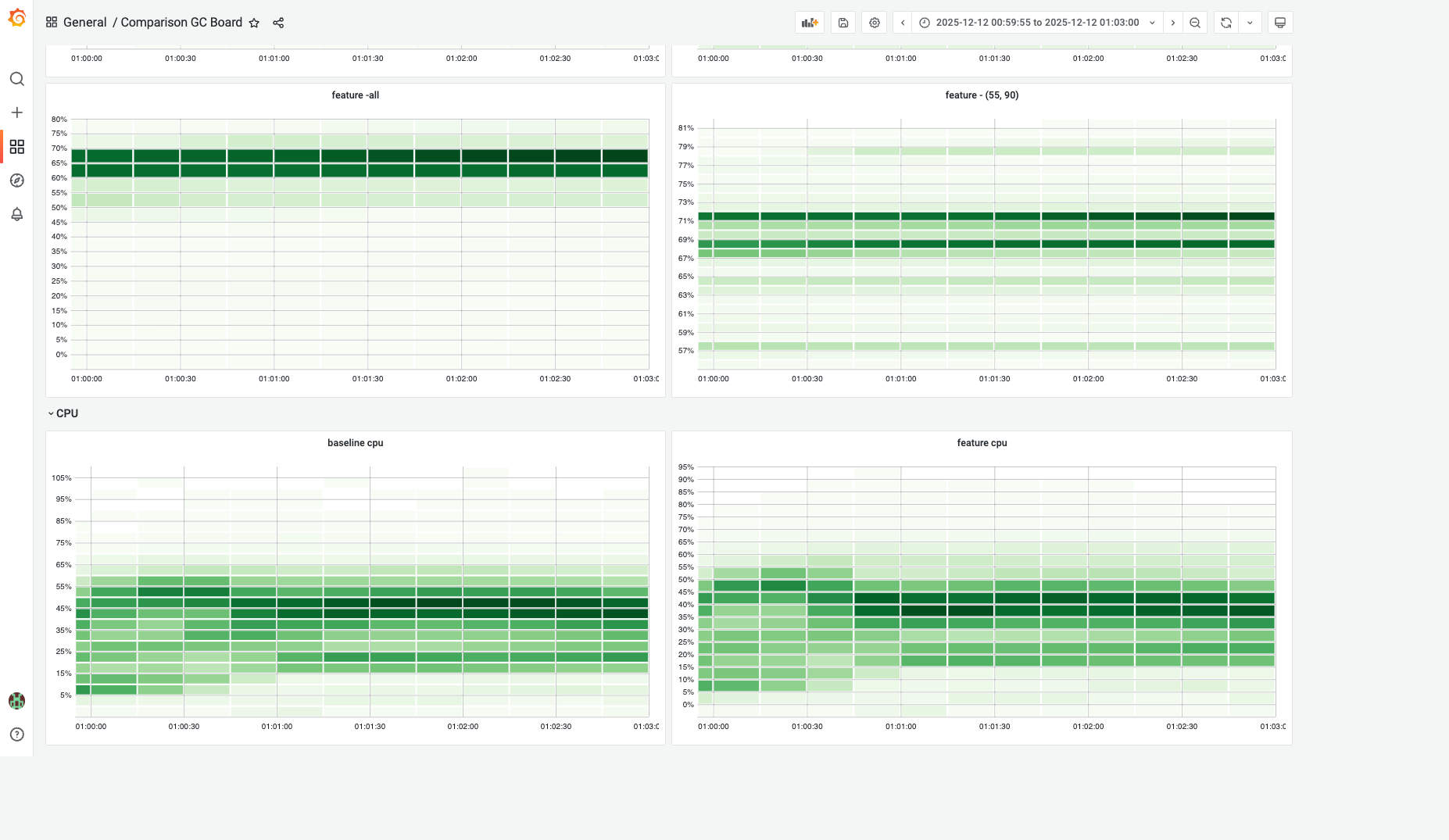
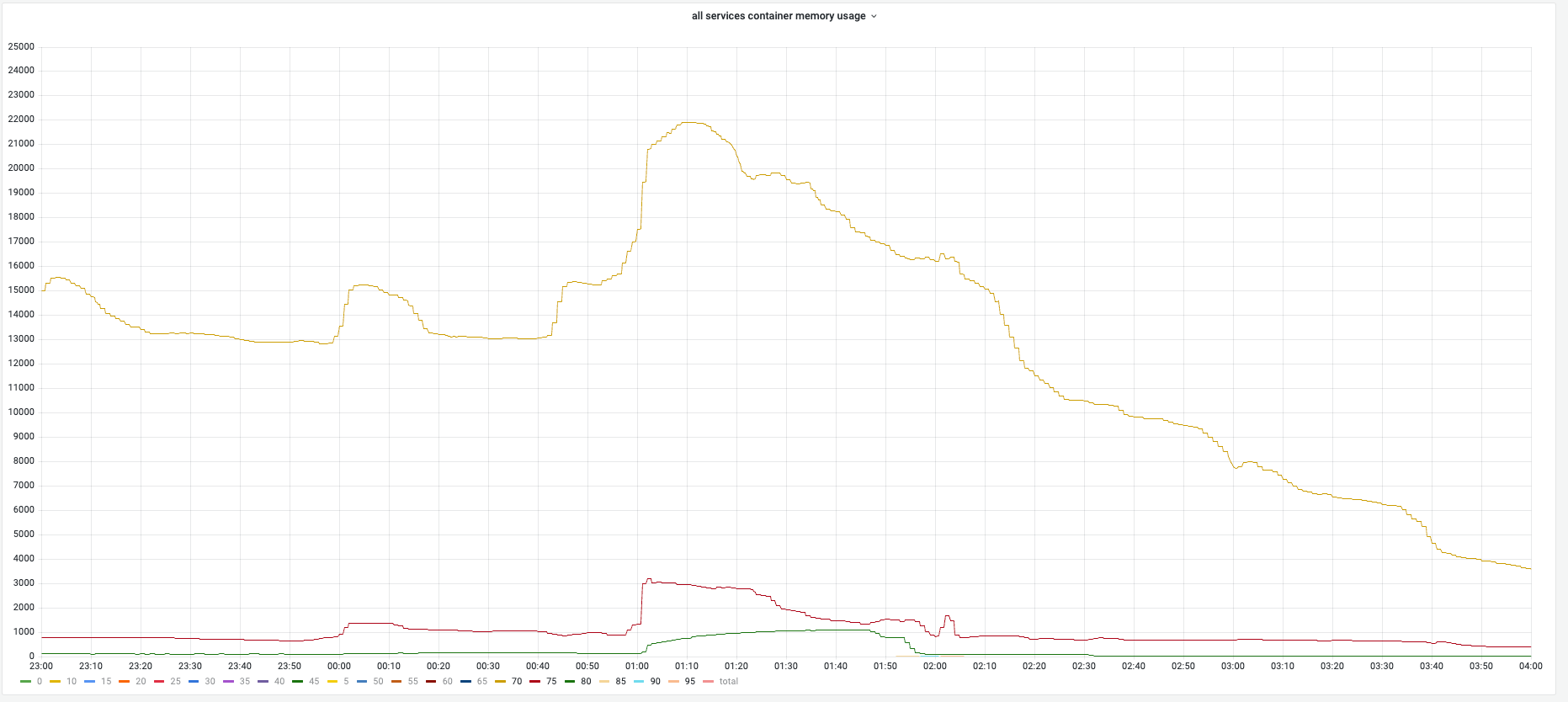
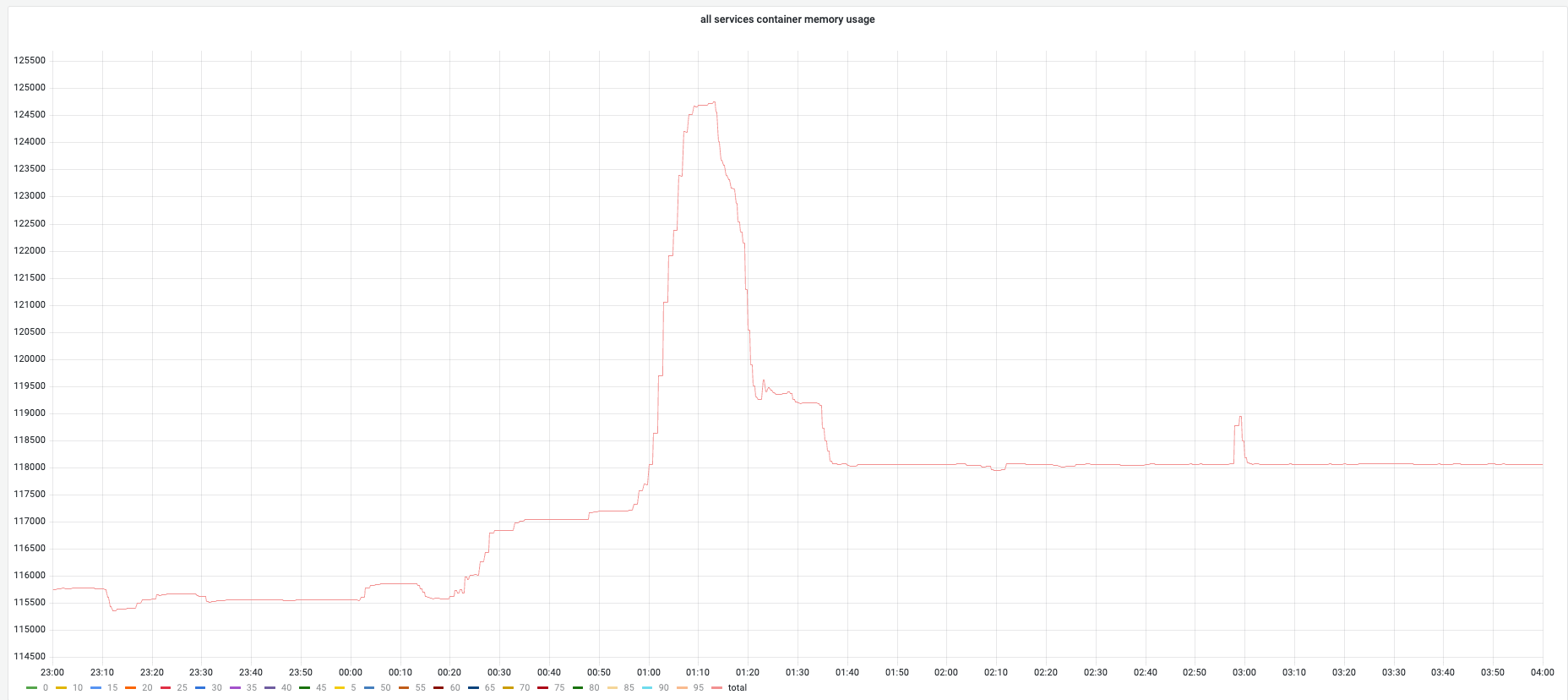
GC调优通过提高实例内存利用率,更少的触发GC,通过减少GC cpu使用率降低app CPU使用率。 在GC调优中,绝大部分容器内存使用符合预期,保持稳定。
feature的内存变化状况¶
All images are put in ID region.
- campaign前
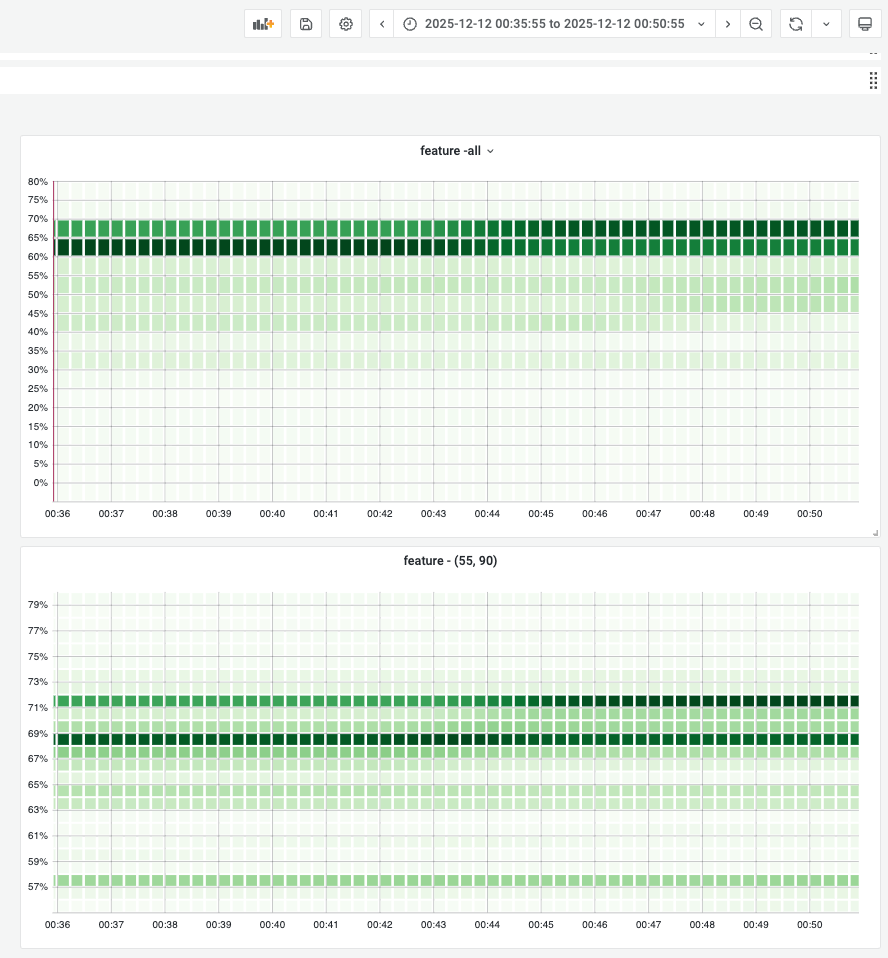
- campaign中
FEATURE的变化图campaign期间内存牢牢的锁定在预设的界限处,整套方案的稳定性较高。
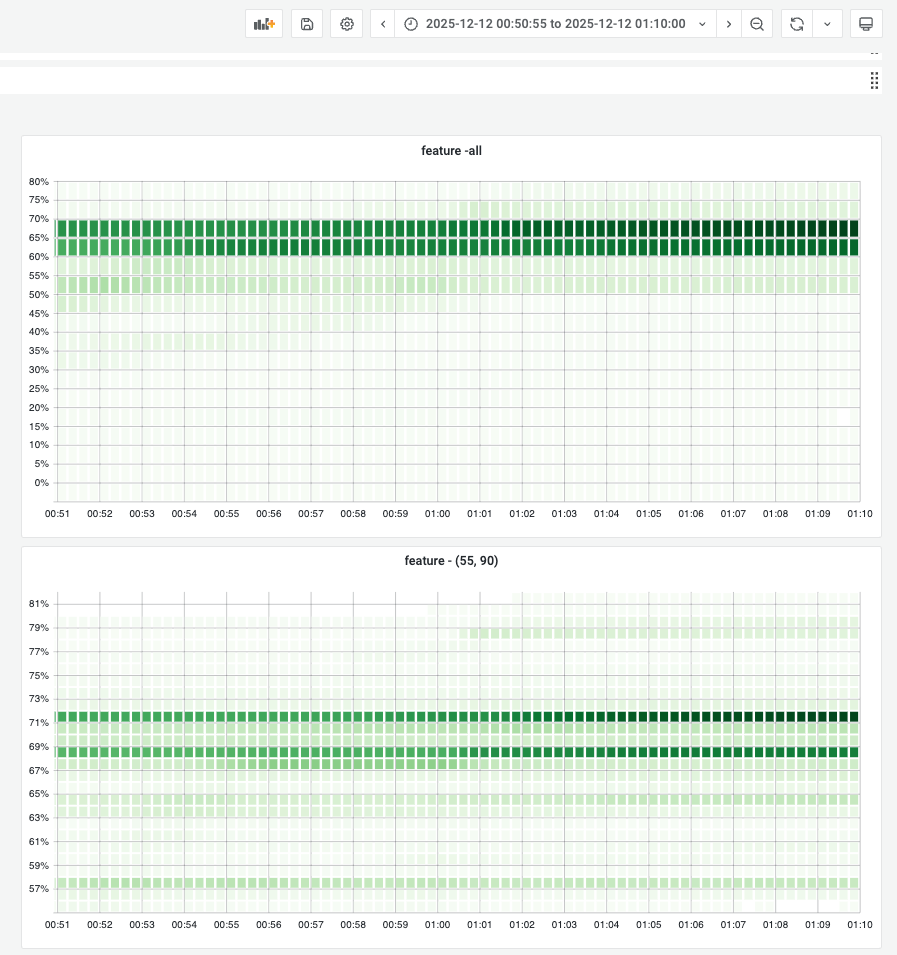
- campaign后
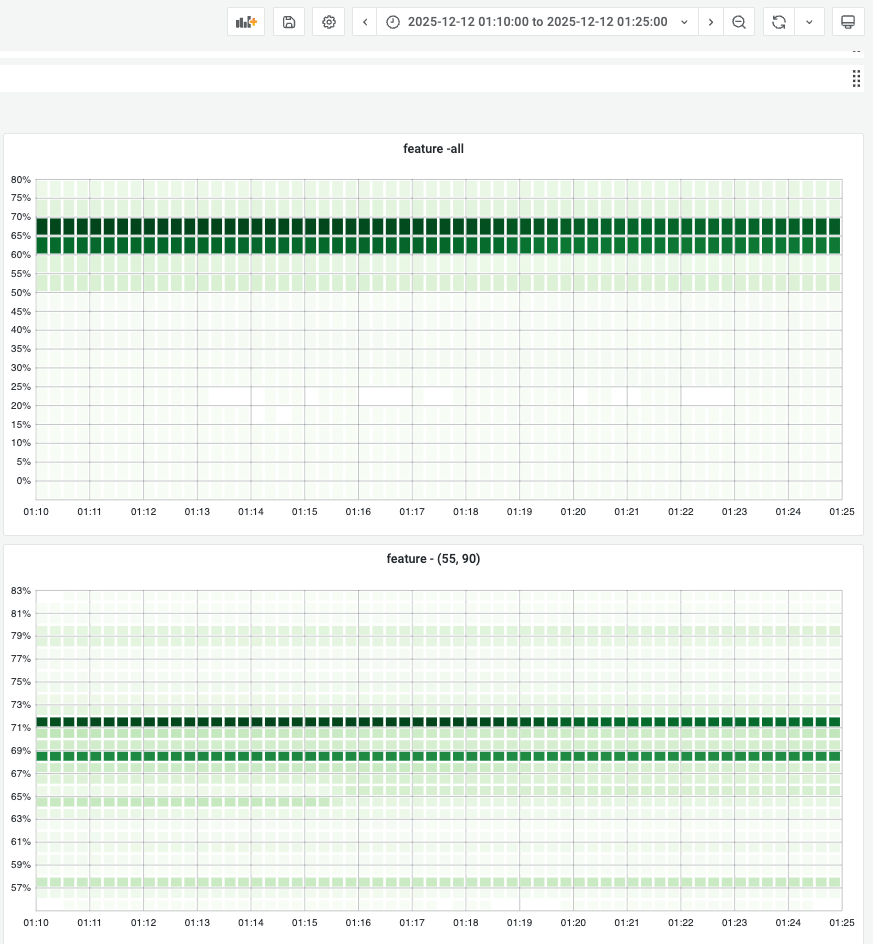
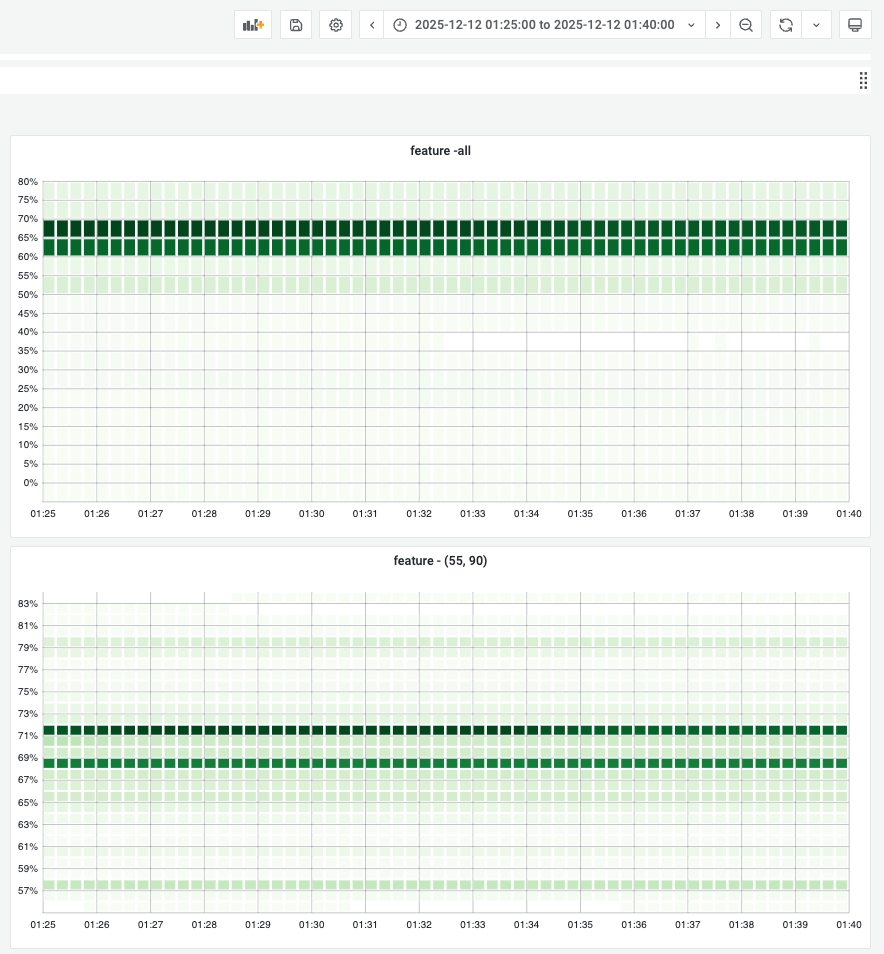
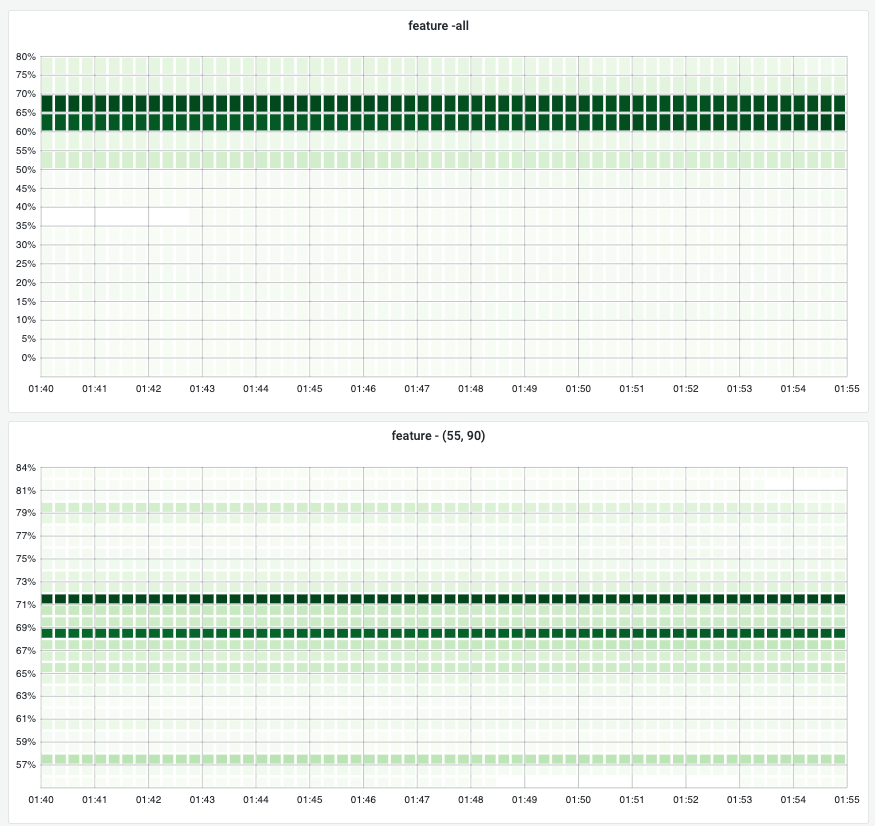
- 整体的内存变化图
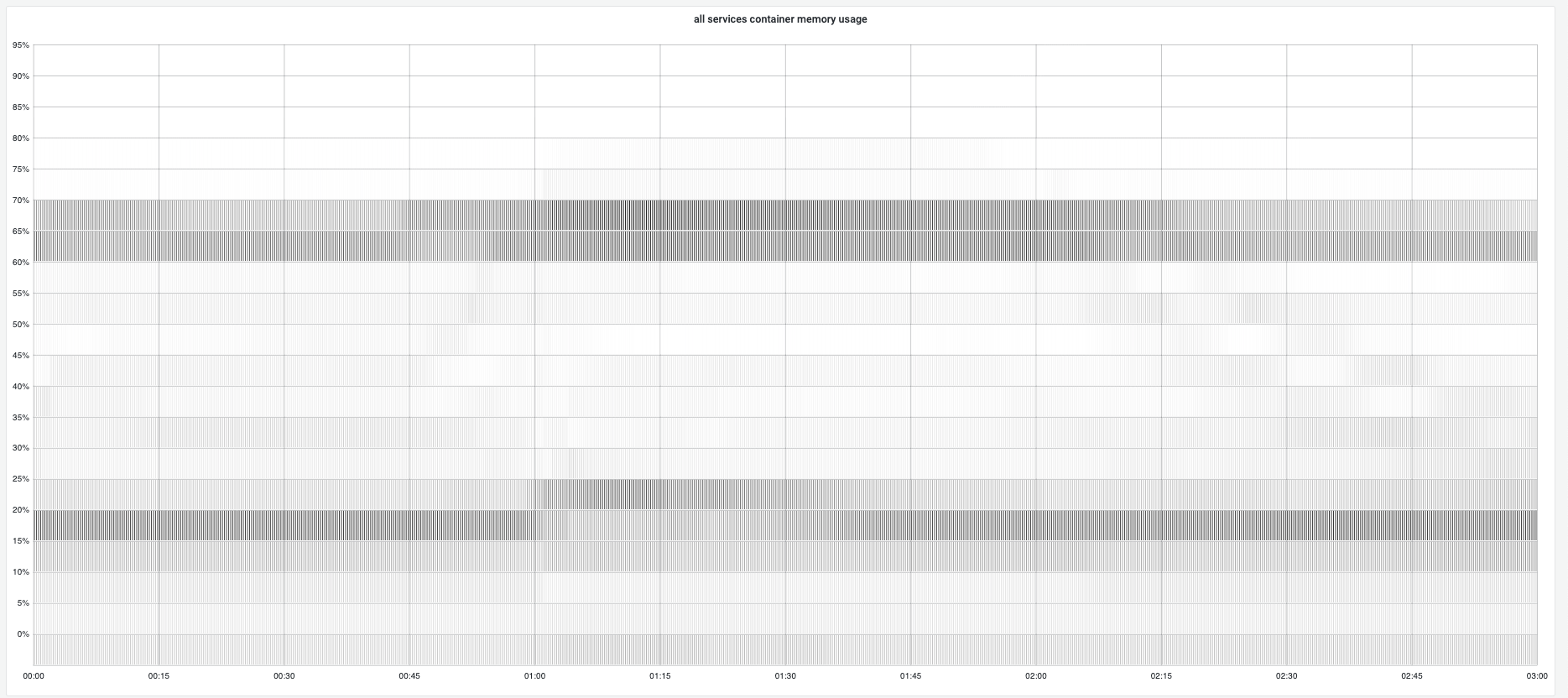
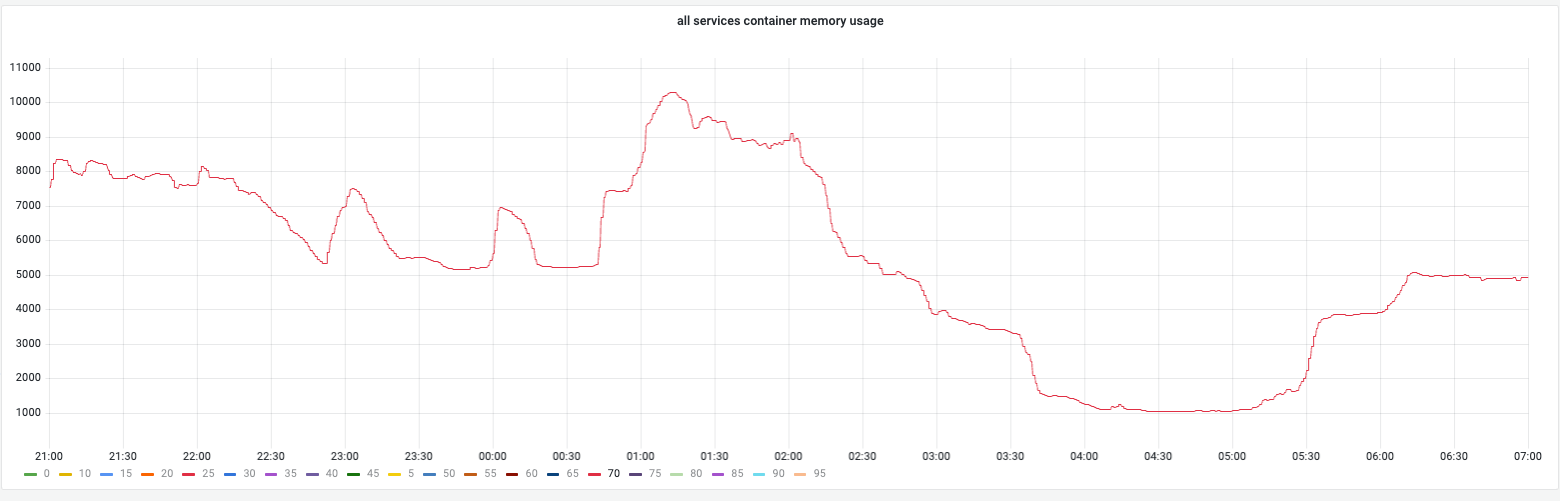
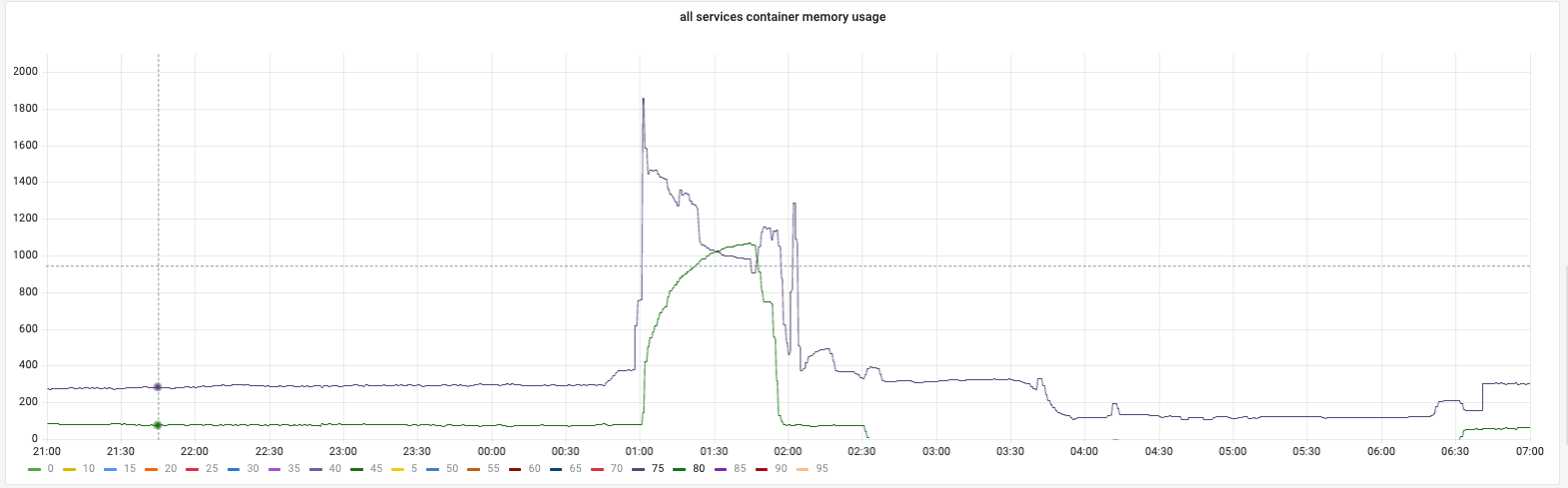
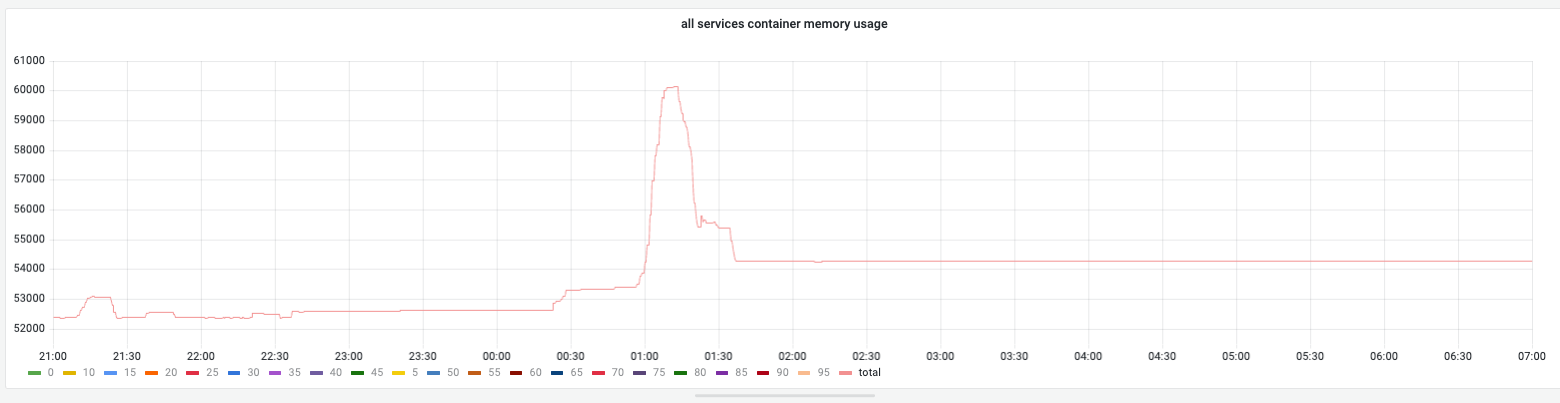
feature的内存变化总体状况¶
STW和App Latency¶
无事故,且基于我们SOP修改业务端修改告警后,无任何告警,平稳完成campaign。
数据计算方法¶
计算原理¶
CPU节省的计算采用了复杂的归一化方法,将CPU成本分解为三个部分: 1. Business Logic(业务逻辑) 2. JSON(序列化/反序列化) 3. GC(垃圾回收)
核心公式:
归一化处理¶
由于baseline和featured期间的QPS、alloc rate等指标不同,需要进行归一化处理才能fair comparison:
-
GC归一化:
通过allocation rate归一化,消除内存分配频率差异的影响 -
JSON归一化:
通过QPS加权计算,消除流量差异的影响 -
Business Logic:
节省计算¶
计算Ratio:
proj_cpu_rate_ratio = proj_variant_total / proj_baseline_total
proj_json_saving_ratio = (proj_baseline_json - proj_variant_json) / proj_baseline_total
proj_gc_saving_ratio = (proj_baseline_gc - proj_variant_gc) / proj_baseline_total
Quota节省:
proj_json_quota_saving = proj_json_saving_ratio × quota
proj_gc_quota_saving = proj_gc_saving_ratio × quota
proj_quota_saving = (1 - proj_cpu_rate_ratio) × quota
Projected vs Actual¶
- Projected(预估):
Σ(ratio × quota)= 34.4k cores - 基于CPU quota的理论最大节省
-
假设所有改善都能转化为quota回收
-
Actual(实际):
Σ(ratio × actual_cpu_usage)= 17k cores - 基于实际CPU使用量的真实回收
- 实际回收率:17k / 34.4k ≈ 49.4%
为什么实际回收率只有~50%? 1. 实际CPU使用量 < quota(有安全buffer) 2. 不是所有使用率改善都能转化为quota回收 3. 保守策略,保留了安全余量
量化收益(12.12 Campaign)¶
CPU节省¶
- 节省:17k CPU cores
- CPU quota:735k cores
- 降低比例:2.3%
- 预估准确性:~95%(actual 17k vs estimated 18k for known services)
GC性能改善¶
- GC cycles减少:84.1%(从48.3次/2min → 7.7次/2min)
- GC CPU cost降低:82.0%(从146,766 → 26,393,加权平均)
- 计算方式:
(Σ(baseline_gc_avg - featured_gc_avg) × count) / Σ(baseline_gc_avg × count) - 样本数:119,775个数据点,来自gc_camp_1212_statistic.json
成本节省¶
- CPU单价:~$35/core/year
- 年度节省:$0.6M
- 计算:17,000 cores × $35 = $597k ≈ $0.6M
规模数据¶
- 服务数量:76 impactful services
- Instances数量:65.2k(featured),约55k baseline
- 总CPU quota:735k cores
- 总内存quota:1.11 PB
数据来源¶
- 统计数据:
gc_camp_1212_statistic.json(498个services,119,775个样本) - 收益计算:
campaign_1212_benefit.csv(765个service-region units) - Projected计算:
analyzer/src/campaign_1212_benefit.json(925个services)
服务选择¶
目前有6700+服务(286k instances)在我们框架上,我在可行性分析阶段对所有适用服务进行分析,基于以下标准进行服务选择:
- 较大CPU quota和充裕的内存,忽略70+%内存使用不适用于gc tuner的服务
- 选择top 100服务,确保rollout进度不会因为大规模数量拖累,同时可以按时在p0级别的campaign中计算收益。
通过选取满足以上条件的服务,我们在尽可能覆盖大比例cpu和rollout工作量中找到了平衡。
如何观察¶
gc tuner的影响数目通过我们的动态开关打开,完成特定比例线上业务的服务打开gc tuner开关,通过gc tuner暴露的metrics了解受影响的 instances。gc tuner由动态开关分发的配置作为输入,检查当前live heap,memory usage来决定是否要调,有一个专门的gc_tuner_status来标识目前gc tuner的状态。 除此之外,会使用go runtime metrics附加检查gogc值和target heap是否符合预期。 安全保护我们额外暴露了容器内的rss,主要目的是因为集群暴露的ip是容器级别的,和我们业务暴露metrics里记录的是instance级别的ip,方便查询。gc tuner自适应所以除了手动变更config关闭之外其他安全保护全部都是gc tuner自动完成并变更metrics的。
top5 CPU qupta service.
| ID | Memory | CPU Cores | Instance Count |
|---|---|---|---|
| product_price.business | 99.1 TiB | 50.7 K | 6.36 K |
| bass.promotion_bass_item | 96.8 TiB | 49.5 K | 6.22 K |
| price_bound.corecritical | 93.2 TiB | 47.7 K | 5.97 K |
| listing_aggregation.bassiteminfo | 74.4 TiB | 39.1 K | 4.91 K |
| mp_usage.api | 71.6 TiB | 36.5 K | 9.18 K |
核心需求是降低CPU使用量.
数据采集¶
- TODO: 容器cpu使用量如何拿到的,需要复习
- TODO: cpu trottling? 我们没这个东西
- P99 + 错误率 + OOM/重启次数
Latency Collecting¶
查询:拉 10min 窗口内的 p50/p95/p99 时间序列点
对每个服务、每个指标(API latency、STW)、每个分位(50/95/99),拉回 10min 的点序列 x(t)(15s 间隔大约 40 个点)。
窗口内加工:对每条点序列提取“窗口特征”
主代表值:
repr = median(x(t)) (推荐默认主口径)
窗口内偏坏水平(你说的 p95-of-time):
hi = quantile(x(t), 0.95)
含义:这 10min 里 最差的 5% 时间 大概有多差(比 max 稳得多)。
稳定性/抖动(非常有用,帮你识别“p99 长尾抖动”):
instability = hi / repr (或 hi - repr 也行)
baseline vs feature:开始做比较
3.1 对每个服务、每个分位(p50/p95/p99)计算:
绝对变化:Δ = after_repr - before_repr
相对变化:r = (after_repr - before_repr) / before_repr(before 太小用 eps 截断)
然后定义 变差条件(deadband,避免噪声):
变差 = (r > r0) AND (Δ > Δ0)
或更宽松:变差 = (r > r0) OR (Δ > Δ0)
阈值怎么来?先给一个可用默认值(你后续可从数据反推校准):
p50:r0=3%,Δ0=0.2ms
p95:r0=5%,Δ0=1ms
p99:r0=8~10%,Δ0=2ms(按你们量级调)
3.1 用ln(after/before)(log ratio)来跨服务理解?
不同服务基线差异巨大(p99 可能从 5ms 到 500ms),直接平均相对变化 r 往往会被极端值拖偏,而且“+100%/-50%”不对称。
ℓ=ln( before/ after )
3.2 分解与稳健化p99 长尾效应
输出“尾巴是否更重”的形态指标,对每个服务算:
tail_ratio = repr_p99 / repr_p50(或 repr_p99 / repr_p95)
执行步骤:
查询,获得原始的[p50], [p95], [p99]数据
加工:median函数和hi95函
进行比较即可